Photo Credit : Spring Source
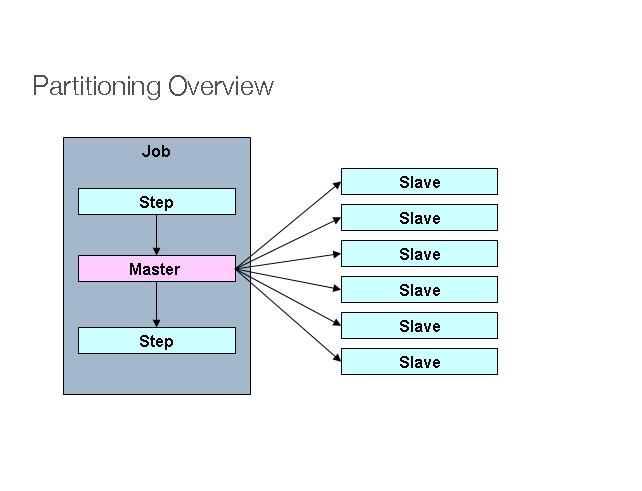
In Spring Batch, “Partitioning” is “multiple threads to process a range of data each”. For example, assume you have 100 records in a table, which has “primary id” assigned from 1 to 100, and you want to process the entire 100 records.
Normally, the process starts from 1 to 100, a single thread example. The process is estimated to take 10 minutes to finish.
Single Thread - Process from 1 to 100
In “Partitioning”, we can start 10 threads to process 10 records each (based on the range of ‘id’). Now, the process may take only 1 minute to finish.
Thread 1 - Process from 1 to 10
Thread 2 - Process from 11 to 20
Thread 3 - Process from 21 to 30
......
Thread 9 - Process from 81 to 90
Thread 10 - Process from 91 to 100
To implement “Partitioning” technique, you must understand the structure of the input data to process, so that you can plan the “range of data” properly.
1. Tutorial
In this tutorial, we will show you how to create a “Partitioner” job, which has 10 threads, each thread will read records from the database, based on the provided range of ‘id’.
Tools and libraries used
- Maven 3
- Eclipse 4.2
- JDK 1.6
- Spring Core 3.2.2.RELEASE
- Spring Batch 2.2.0.RELEASE
- MySQL Java Driver 5.1.25
P.S Assume “users” table has 100 records.
id, user_login, user_passs, age
1,user_1,pass_1,20
2,user_2,pass_2,40
3,user_3,pass_3,70
4,user_4,pass_4,5
5,user_5,pass_5,52
......
99,user_99,pass_99,89
100,user_100,pass_100,76
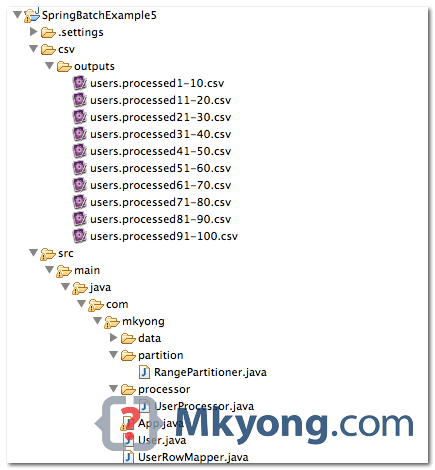
2. Project Directory Structure
Review the final project structure, a standard Maven project.

3. Partitioner
First, create a Partitioner implementation, puts the “partitioning range” into the ExecutionContext. Later, you will declare the same fromId and tied in the batch-job XML file.
In this case, the partitioning range is look like the following :
Thread 1 = 1 - 10
Thread 2 = 11 - 20
Thread 3 = 21 - 30
......
Thread 10 = 91 - 100
package com.mkyong.partition;
import java.util.HashMap;
import java.util.Map;
import org.springframework.batch.core.partition.support.Partitioner;
import org.springframework.batch.item.ExecutionContext;
public class RangePartitioner implements Partitioner {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> result
= new HashMap<String, ExecutionContext>();
int range = 10;
int fromId = 1;
int toId = range;
for (int i = 1; i <= gridSize; i++) {
ExecutionContext value = new ExecutionContext();
System.out.println("\nStarting : Thread" + i);
System.out.println("fromId : " + fromId);
System.out.println("toId : " + toId);
value.putInt("fromId", fromId);
value.putInt("toId", toId);
// give each thread a name, thread 1,2,3
value.putString("name", "Thread" + i);
result.put("partition" + i, value);
fromId = toId + 1;
toId += range;
}
return result;
}
}
4. Batch Jobs
Review the batch job XML file, it should be self-explanatory. Few points to highlight :
- For partitioner, grid-size = number of threads.
- For pagingItemReader bean, a jdbc reader example, the
#{stepExecutionContext[fromId, toId]}values will be injected by theExecutionContextin rangePartitioner. - For itemProcessor bean, the
#{stepExecutionContext[name]}values will be injected by theExecutionContextin rangePartitioner. - For writers, each thread will output the records in a different csv files, with filename format –
users.processed[fromId]}-[toId].csv.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:util="http://www.springframework.org/schema/util"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util-3.2.xsd
">
<!-- spring batch core settings -->
<import resource="../config/context.xml" />
<!-- database settings -->
<import resource="../config/database.xml" />
<!-- partitioner job -->
<job id="partitionJob" xmlns="http://www.springframework.org/schema/batch">
<!-- master step, 10 threads (grid-size) -->
<step id="masterStep">
<partition step="slave" partitioner="rangePartitioner">
<handler grid-size="10" task-executor="taskExecutor" />
</partition>
</step>
</job>
<!-- each thread will run this job, with different stepExecutionContext values. -->
<step id="slave" xmlns="http://www.springframework.org/schema/batch">
<tasklet>
<chunk reader="pagingItemReader" writer="flatFileItemWriter"
processor="itemProcessor" commit-interval="1" />
</tasklet>
</step>
<bean id="rangePartitioner" class="com.mkyong.partition.RangePartitioner" />
<bean id="taskExecutor" class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
<!-- inject stepExecutionContext -->
<bean id="itemProcessor" class="com.mkyong.processor.UserProcessor" scope="step">
<property name="threadName" value="#{stepExecutionContext[name]}" />
</bean>
<bean id="pagingItemReader"
class="org.springframework.batch.item.database.JdbcPagingItemReader"
scope="step">
<property name="dataSource" ref="dataSource" />
<property name="queryProvider">
<bean
class="org.springframework.batch.item.database.support.SqlPagingQueryProviderFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="selectClause" value="select id, user_login, user_pass, age" />
<property name="fromClause" value="from users" />
<property name="whereClause" value="where id >= :fromId and id <= :toId" />
<property name="sortKey" value="id" />
</bean>
</property>
<!-- Inject via the ExecutionContext in rangePartitioner -->
<property name="parameterValues">
<map>
<entry key="fromId" value="#{stepExecutionContext[fromId]}" />
<entry key="toId" value="#{stepExecutionContext[toId]}" />
</map>
</property>
<property name="pageSize" value="10" />
<property name="rowMapper">
<bean class="com.mkyong.UserRowMapper" />
</property>
</bean>
<!-- csv file writer -->
<bean id="flatFileItemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter"
scope="step" >
<property name="resource"
value="file:csv/outputs/users.processed#{stepExecutionContext[fromId]}-#{stepExecutionContext[toId]}.csv" />
<property name="appendAllowed" value="false" />
<property name="lineAggregator">
<bean
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="delimiter" value="," />
<property name="fieldExtractor">
<bean
class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor">
<property name="names" value="id, username, password, age" />
</bean>
</property>
</bean>
</property>
</bean>
</beans>
The item processor class is used to print out the processing item and current running “thread name” only.
package com.mkyong.processor;
import org.springframework.batch.item.ItemProcessor;
import com.mkyong.User;
public class UserProcessor implements ItemProcessor<User, User> {
private String threadName;
@Override
public User process(User item) throws Exception {
System.out.println(threadName + " processing : "
+ item.getId() + " : " + item.getUsername());
return item;
}
public String getThreadName() {
return threadName;
}
public void setThreadName(String threadName) {
this.threadName = threadName;
}
}
5. Run It
Loads everything and run it… 10 threads will be started to process the provided range of data.
package com.mkyong;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class PartitionApp {
public static void main(String[] args) {
PartitionApp obj = new PartitionApp ();
obj.runTest();
}
private void runTest() {
String[] springConfig = { "spring/batch/jobs/job-partitioner.xml" };
ApplicationContext context = new ClassPathXmlApplicationContext(springConfig);
JobLauncher jobLauncher = (JobLauncher) context.getBean("jobLauncher");
Job job = (Job) context.getBean("partitionJob");
try {
JobExecution execution = jobLauncher.run(job, new JobParameters());
System.out.println("Exit Status : " + execution.getStatus());
System.out.println("Exit Status : " + execution.getAllFailureExceptions());
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("Done");
}
}
Console output
Starting : Thread1
fromId : 1
toId : 10
Starting : Thread2
fromId : 11
toId : 20
Starting : Thread3
fromId : 21
toId : 30
Starting : Thread4
fromId : 31
toId : 40
Starting : Thread5
fromId : 41
toId : 50
Starting : Thread6
fromId : 51
toId : 60
Starting : Thread7
fromId : 61
toId : 70
Starting : Thread8
fromId : 71
toId : 80
Starting : Thread9
fromId : 81
toId : 90
Starting : Thread10
fromId : 91
toId : 100
Thread8 processing : 71 : user_71
Thread2 processing : 11 : user_11
Thread3 processing : 21 : user_21
Thread10 processing : 91 : user_91
Thread4 processing : 31 : user_31
Thread6 processing : 51 : user_51
Thread5 processing : 41 : user_41
Thread1 processing : 1 : user_1
Thread9 processing : 81 : user_81
Thread7 processing : 61 : user_61
Thread2 processing : 12 : user_12
Thread7 processing : 62 : user_62
Thread6 processing : 52 : user_52
Thread1 processing : 2 : user_2
Thread9 processing : 82 : user_82
......
After the process is completed, 10 CSV files will be created.
1,user_1,pass_1,20
2,user_2,pass_2,40
3,user_3,pass_3,70
4,user_4,pass_4,5
5,user_5,pass_5,52
6,user_6,pass_6,69
7,user_7,pass_7,48
8,user_8,pass_8,34
9,user_9,pass_9,62
10,user_10,pass_10,21
6. Misc
6.1 Alternatively, you can inject the #{stepExecutionContext[name]} via annotation.
package com.mkyong.processor;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
import com.mkyong.User;
@Component("itemProcessor")
@Scope(value = "step")
public class UserProcessor implements ItemProcessor<User, User> {
@Value("#{stepExecutionContext[name]}")
private String threadName;
@Override
public User process(User item) throws Exception {
System.out.println(threadName + " processing : "
+ item.getId() + " : " + item.getUsername());
return item;
}
}
Remember, enable the Spring component auto scanning.
<context:component-scan base-package="com.mkyong" />
6.2 Database partitioner reader – MongoDB example.
<bean id="mongoItemReader" class="org.springframework.batch.item.data.MongoItemReader"
scope="step">
<property name="template" ref="mongoTemplate" />
<property name="targetType" value="com.mkyong.User" />
<property name="query"
value="{
'id':{$gt:#{stepExecutionContext[fromId]}, $lte:#{stepExecutionContext[toId]}
} }"
/>
<property name="sort">
<util:map id="sort">
<entry key="id" value="" />
</util:map>
</property>
</bean>
Done.
This partitioning method fails if (gridSize * range) < MAX(ROWNUM)… In other words, if you have more records than number of threads times the size of each partition (range), then the remainder will NEVER get processed, unless, of course, the processed values are somehow discarded from the subsequent resultsets, making room for the unprocessed ones. This cannot happen for unique ID filtering… Please add a sample for dynamic partitioning, where the overall size of the resultset is not know in advance, and the number of threads (grid size) and/or the partition size (range) needs to be adjusted dynamically to evenly spread the load of processing all the rows in the unchanging in terms of filter keys and size resultset.
Hello, i know this was years ago, but do you have an example with dynamic processing ?
Hi,
Actually i have a requirement that i need to read 1 million records from DB and need to write it in a file with some conditions. but the thing is, it got struck while reading 1 million records from DB. no movements there. also i don’t want to create 10 files like your example. i want to put all the details in a file. can you please suggest me some solutions?
Hi Mkyong,
This program for mongodb does not works properly even the code is not complete. Could you guide us how we can read data from mongodb using itemReader of Spring Batch mongo? Please help us.
I need to Read data from database Using SpringDataJPA with Spring batch RepositoryItemReader
by passing Id
Great article! I am facing an issue while using stepExecutionContext. it’s giving me null values. Can anyone please help me? Here’s my question : https://stackoverflow.com/q/45265797/1934211
Instead of writing to different files for the itemWriter can we have all the threads write to the same file.
If I have 100 records and I create only 5 threads and pageSize = 10. Then how the other 50 records will get processed because each thread will process only 10 records. Can I make look partitioner as well?
I am getting below error in logs
ChunkMonitor.open – No ItemReader set (must be concurrent step), so ignoring offset data.
And no data is getting read for processing
scope=”step” and saveState=false
Instead of writing to different files I am writing to the same file. But the problem is since they are threads, whichever thread completes is going to write to the file and so the file will not have a sorted list of values. Is there a way to sequence the thread write only so that they are written to the file in a sorted order.
Hello All –
I’m going through some issues while using partitioner. Any inputs provided will be greatly appreciated!
Ex: 10 threads and each executing 5 xml files.
1) I use spring batch 2.1 version to implement multi-threading multi-process using partitioner.
2) Job runs fine when I use single thread. If I make it >2 then I get “org.springframework.batch.core.JobInterruptedException:”. This is intermittent.
3) I’m not sure what makes the thread throw this exception since we are using partition there should not be any thread-safe issue. I even tried synchronizing but in vain.
Any inputs provided will be greatly appreciated!
Hi guys,
pls replace “where id >= :fromId and id <= :toId" by "where id > :fromId and id < :toId" in above example. thanks.
How can i access JobExecutionContext from Partitioner ??
How can i access JobExecutionContext from Partitioner
How can i access JobExecutionContext from Partitioner ??
Hi ,
I am trying the same example but instead of writing to a file , I am writing to a database table. The problem is sometimes the batch job runs fine. Sometimes the number of partitions formed are not executed , I mean reader is not executed for some partitions.
Can you pls post some example of partitioning where reading and writing is done from database instead of file ?
Thanks
Dhaval
Thanks Young.Exactly what I need and it worked!
Thanks
how do we partition if i cannot pass the parameters to where clause?
Hi Mykong, This is really helpful. Can you please provide details on how to specify the number of threads we want to run in parallel at any given time. In the above example, if I want to have only 5 slaves running at any given time so that Thread 1 to Thread 5 will start. Then lets say Thread 3 is able to complete ahead of others. Then I want Thread 6 to start. And it continues till all the threads are processed.
smart exmaple
Lets say I decide to use a SimpleAsyncTaskExecutor with a concurrency limit of 5 and my partitioner has a gridSize of 10. I assume this means that the next 5 threads will wait for the current 5 threads to finish before starting.
Hi Mkyong,
Your partitioning example works like charm. I had a requirement where I had to pass parameters to the partitioner from the joblauncher(i.e. the main program) . I tried a lot but not able to get the parameters in Partitioner. Can you please help me on this.Thanks in advance
Thanks, nice post
Hi, I have a use case where I want to use the batch job with different sql query params . Say I want to find the users of different groups. Therefor the same job will for different groups. Can I use partition to get the result?
Or I have to use the repeat strategy.?
Why not use the new Java 7 ForkJoinPool feature to perform this task?
I can imagine it’s more efficient.
– Ed
Hi Greetings,
Do we have any open source code for creating mhtml using java ?
I have already tried with Jtidy API(sourceforge) ,yes it used to create the mhtml file,but i couldnot able to open in Internet Explorer.
http://www.devx.com/tips/Tip/41768
Please share your valuable suggestion,
Thanks in Advance.
Vasanth Dha