Apache Solr Hello World Example

Apache Solr is an Open-source REST-API based Enterprise Real-time Search and Analytics Engine Server from Apache Software Foundation. It’s core Search Functionality is built using Apache Lucene Framework and added with some extra and useful features. It is written in Java Language.
SOLR stands for Searching On Lucene w/Replication. It’s main functionalities are indexing and serching. Like ElasticSearch, it is also a Document-based NoSQL Data Store.
It’s official website: http://lucene.apache.org/solr/. Latest version of Solr is 6.4.2, which was released on 7th March 2017.
Apache Solr Features:-
- An Open-source
- Supports Full-text Search and Faceted Navigation Feature
- Hit highlighting
- Relevant Results
- Uses Apache Lucene Inverted Index to index it’s documents.
- Supports Recommendations and Spell Suggestions
- Supports Auto-Completion
- Suppots Geo-Spatial Search
- Supports REST Based API (JSON over HTTP)
- Supports Real-time Search and Analytics
- Latest version of Solr (Version 5.x or later) supports Distributed and Colud Technology.
- As it’s written, it supports Cross-platform Feature.
- Built-in Security for Authentication and Authorization
- Supports Streaming
Advantages or Benefits of Apache Solr:-
- An Open-source
- It has very useful Administrative Interface.
- Light Weight with REST API
- It is very fast, simple, powerful and flexible search engine
- Unlike ElasticSearch, it supports not only JSON format, other useful formats too: XML, PHP, Ruby, Python, XSLT, Velocity and custom Java binary output formats over HTTP.
- Highly Available. Easy and Highly Scalable. Robust, fault tolerant and reliable search engine.
- Schema free data store. However, if required we can create a schema to support our data.
- Fast Search Performance because of Apache Lucene Inverted Index.
- Supports both Structured and UN-Structured Data
- Supports Distributed, Sharding, Replication, Clustering and Multi-Node Architecture
- Supports Bulk Operations
- Easily Extendable with new plugins
- Supports Caching Data
- Useful for BigData Environments
- Unlike ElasticSearch, it supports MapReduce algorithm
Drawbacks or Limitations of Apache Solr:-
- Not useful as a Primary Data Store. Only useful as Secondary Data Store.
- Not an ACID compliant Data Store
- Does not support Transactions and Distributed Transactions
- Does NOT supports Joins and Complex Queries
- Does NOT useful to work with Normalized Data
Popular Clients who are using Apache Solr:-
- CNET,Krugle, M TV
- Flipkart.com, Sourceforge.net, guardian.co.uk
- eBay, digg
- AT&T Interactive
- Goldman Sachs
- AOL Music, AOL Travel, AOL YellowPages
- Disney
- Apple, Inc.
- More clients refer to this link
Popular Hadoop distributions like Cloudera, Hortonworks and MapR uses Apache Solr internally to support Search Functionality.
As we know, Apache Solr is written in Java. So, we should have Java/JRE in our System Path to use it. Please install and setup Java Environment properly. Apache Solr 5.x needs Java 7 or later. Apache 6.x needs Java 8 or later.
We can use Apache Solr in two flavors:
- Standalone Apache Solr Server
- Cloud and Distributed Apached Solr Server
In this tutorial, we are going to use the Standalone Apache Solr Server v6.4.2 to demonstrate our examples.
In initial versions of Apache Solr does not support Colud feature. From Apache Solr 4.0 release onwards, it supports Cloud by using SolrCloud component.
1. Install Apache Solr Locally
Please follow these steps to setup Standalone Apache Solr Server locally in Windows, Linux-Based (Like Ubuntu) or Mac OS Environments.
To download the latest Apache Solr, refer to this official download link
1.1 Windows Environment
- Download latest version of Apache Solr
- Extract zip file to Local Filesystem
- Set Environment Variables
Use this link to download Apache Solr V. 6.4.2. You will get solr-6.4.2.zip for Windows environments.
Extracted solr-6.4.2.zip file to F:\solr-6.4.2
Let us assume SOLR_HOME=F:\solr-6.4.2
PATH=${SOLR_HOME}\bin
1.2 Linux or Mac Environment
- Download latest version of Apache Solr
- Extract zip file
Use this link to download Apache Solr V. 6.4.2. You will get solr-6.4.2.tgz for Linux or Mac Environments.
$ tar -xvf solr-6.4.2.tgz
Let us assume SOLR_HOME=/home/rambabu/solr-6.4.2
export PATH=${SOLR_HOME}\bin
Now we have installed Apache Solr successfully.
2. Start/Stop Apache Solr Locally
Some commands to manipulate Apache Solr Server.
2.1 Check Status of Apache Solr
Before starting the Solr Server, please execute the following “status” command to know the status.
cd solr-6.4.2
$ ./solr status
No Solr nodes are running.
2.2 Start Apache Solr
$ ./solr start
Archiving 1 old GC log files to /home/rambabu/solr-6.4.2/server/logs/archived
Archiving 1 console log files to /home/rambabu/solr-6.4.2/server/logs/archived
Rotating solr logs, keeping a max of 9 generations
Waiting up to 180 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid=24563). Happy searching!
If we observe the above start command logs, we can understand that Apache Solr server is started at default port number: 8983. Now again execute “status” command to know the server status now.
$ ./solr status
Found 1 Solr nodes:
Solr process 24563 running on port 8983
{
"solr_home":"/home/rambabu/solr-6.4.2/server/solr",
"version":"6.4.2 34a975ca3d4bd7fa121340e5bcbf165929e0542f - ishan - 2017-03-01 23:30:23",
"startTime":"2017-03-22T15:11:30.804Z",
"uptime":"0 days, 0 hours, 5 minutes, 10 seconds",
"memory":"35.3 MB (%7.2) of 490.7 MB"}
Start Apache Solr with different port number
$ ./solr start –p 9000
2.3 Stop Apache Solr
Use “stop” command to stop server
$ ./solr stop
Sending stop command to Solr running on port 8983 ... waiting up to 180 seconds to allow Jetty process 24563 to stop gracefully.
2.4 Restart Apache Solr
$ ./solr restart
Sending stop command to Solr running on port 8983 ... waiting up to 180 seconds to allow Jetty process 19442 to stop gracefully.
Archiving 1 old GC log files to /home/rambabu/solr-6.4.2/server/logs/archived
Archiving 1 console log files to /home/rambabu/solr-6.4.2/server/logs/archived
Rotating solr logs, keeping a max of 9 generations
Waiting up to 180 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid=19691). Happy searching!
As I’m going to use Linux (Ubuntu) OS in this tutorial, I have used commands like
./solr start. If you are using Windows OS, please use jsut solr start.
3. Apache Solr Terminology
We will discuss few important ElasticSearch Terminology: Solr Core, Solr Core, Indexing, Document, Field etc.
3.1 What is a Solr Instance?
In Apache Solr, a Solr Instance is an instance a Solr running in the JVM. In Standalone mode, Solr contains only one instance where as in Cloud mode, it contains one or more instances.
3.2 What is a Solr Core?
In Apache Solr, a Solr Core is also known as simply “Core”. A Core is an Index of texts and fields available in all documents. One Solr Instance can contain one or more Solr Cores.
In other words, a Solr Core = an instance of Apache Lucene Index + Solr Configuration (solr.xml,solrconfig.xml etc.)
PS:- Apache Solr uses the following important configuration files:
- solr.xml
- solrconfig.xml
- core.properties
If you want to experiment Apache Solr as Schama Based Architecture, please refer Apache Solr documentation.
3.3 What is Indexing?
In Apache Lucene or Solr, Indexing is a technique of adding Document’s content to Solr Index so that we can search them easily. Apache Solr uses Apache Lucene Inverted Index technique to Index it’s documents. That’s why Solr provides very fast searching feature.
3.4 What is a Document?
In Apache Solr, a Document is a group of fields and their values. Documents are the basic unit of data we store in Apache Cores. One core can contain one or more Documents.
3.5 What is a Field?
In Apache Solr, a Field is actual data stored in a Document. It is a key & value pair. Key indicates the field name and value contains that Field data. One Document can contain one or more Fields. Apache Solr uses this Field data to index the Docuemnt Content.

Important points to remember:
- Apache Solr Standalone Architecture has only one Solr instance where as Solr Cloud Architecture have more instances.
- Apache Solr uses SolrCloud technology to support Cloud Architecture.
- Each Solr Instance can have zero or more Cores.
- Each core can contain zero or more Documents.
- Each Document can contain zero or more Fields.
- Each Filed contains a Key:Value pair. Key is the name of the Filed and Value is the data of the Field.
As this tutorial is intended only for Apache Solr Standalone Mode, we are not discussing SolrCloud Terminology.
4. Apache Solr Admin Console
Unlike ElasticSearch, Apache Solr has a Web interface or Admin console. It is one of the advantages of Apache Solr. It is useful for Solr administrators and programmers to view Solr configuration details, run queries and analyze document fields in order to fine-tune a Solr configuration etc.
Once we started Apache Solr, we can access its Admin console using: http://localhost:8983/solr/
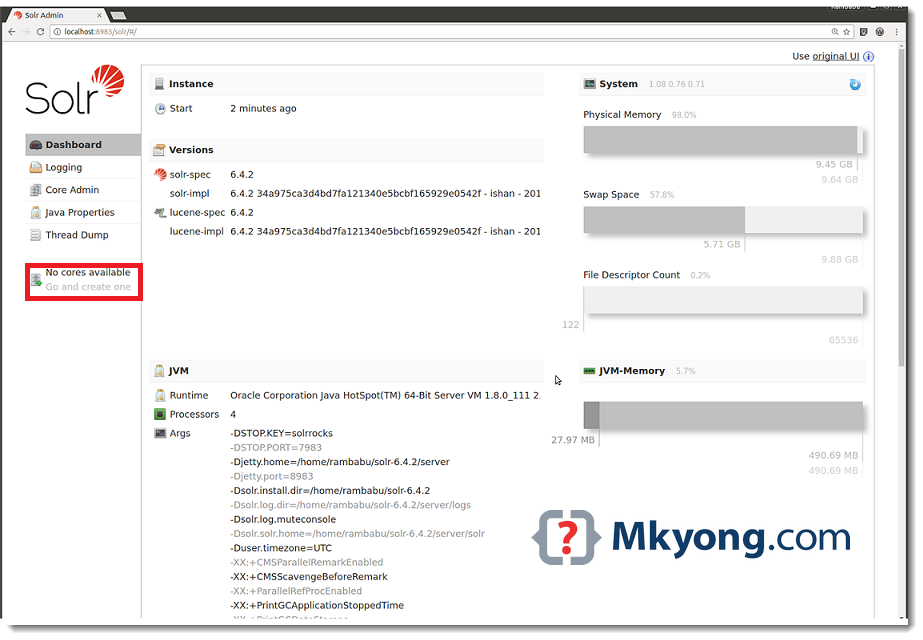
As shown in the above diagram, initially Apache Solr does NOT have any cores, that’s why it shows “No cores available” at left side panel.
We can use this Admin console:
- Create, Update, Delete (Unload) and View Cores
- Create, Update, Delete and View Documents
- Apache Solr Configurations
- Logging information
- Monitoring information
5. Create “helloworld” Apache Solr Core
We can perform Apache Solr operations like CRUD an Apache Core or CRUD a Doucment or Field uses the following ways:
- Apache Solr Comamnds
- Admin Console
- REST API
- CURL Command
First, let us discuss about how to create Core uses Commands and view them in the Admin console.
Before executing these commands, please start Apache Solr using “solr start” command. We can use “create” command to create an Apache Core as shown below:
Create command syntax:-
$ ./solr create -c <SOLR_CORE_NAME>
Here “create” command is used to create Core and “-c” option specifies Solr Core Name.
Create command Example:-
$ ./solr create -c helloworld
Copying configuration to new core instance directory:
/home/rambabu/solr-6.4.2/server/solr/helloworld
Creating new core 'helloworld' using command:
http://localhost:8983/solr/admin/cores?action=CREATE&name=helloworld&instanceDir=helloworld
{
"responseHeader":{
"status":0,
"QTime":1636},
"core":"helloworld"}
If we observe above output, we can understand that “helloworld” core is created successfully. Even we can see the following REST API url in that output to create “helloworld” core.
http://localhost:8983/solr/admin/cores?action=CREATE&name=helloworld&instanceDir=helloworld
Here “action” Query parameter specifies the “CREATE” operation and name defines the Core name and instanceDir specifies a directory name. We can use both name and instanceDir same or different.
After executing this command, if we refresh Admin console, we don’t see “No cores available” at left side panel. Now you can see “Core Selector” option. If we click on that, it will display “helloworld” core in dropdown box. If you select that core, it displays all information at left side panel. It also displays different option just below in that dropdown box:
- Overview
- Documents
- Query
Display overview information about that Core.
To Create/Update/Delete Documents into or from Core.
To query or view Documents or Fields(data).
It also creates a folder “helloworld” under ${SOLR_HOME}/server/solr/ as shown below:

To create an Apache Core with required folder name
Create command Example:-
$ ./solr create -c helloworld -d myhellowolrd
Here our “helloworld” core creates with folder name “myhellowolrd”
6. Add/Update/Import Documents to Core
As we just created “helloworld” Core, it is empty. Does not contain Documents or Data. We can use Apache Solr Admin Console “Documents” option to Add/Update/Import Documents into this core.
We can add Documents by using Content directly in different formats like JSON, XML, Binary, etc or by using the FileUpload option to upload files as Documents directly.
Add Files into “helloworld” Core
- Access Solr Admin Console:
http://localhost:8983/solr/ - Click on “Core Selector” option and select “helloworld” core in dropdown box.
- Click on “Documents” option
- Observe “Request-Handler”, it shows “/update” that means we are going to update Core with Documents
- At Document(s), click on “Choose File” option
- Select “films.json” from ${SOLR_HOME}/example/films/
- Click on “Submit Document” button.
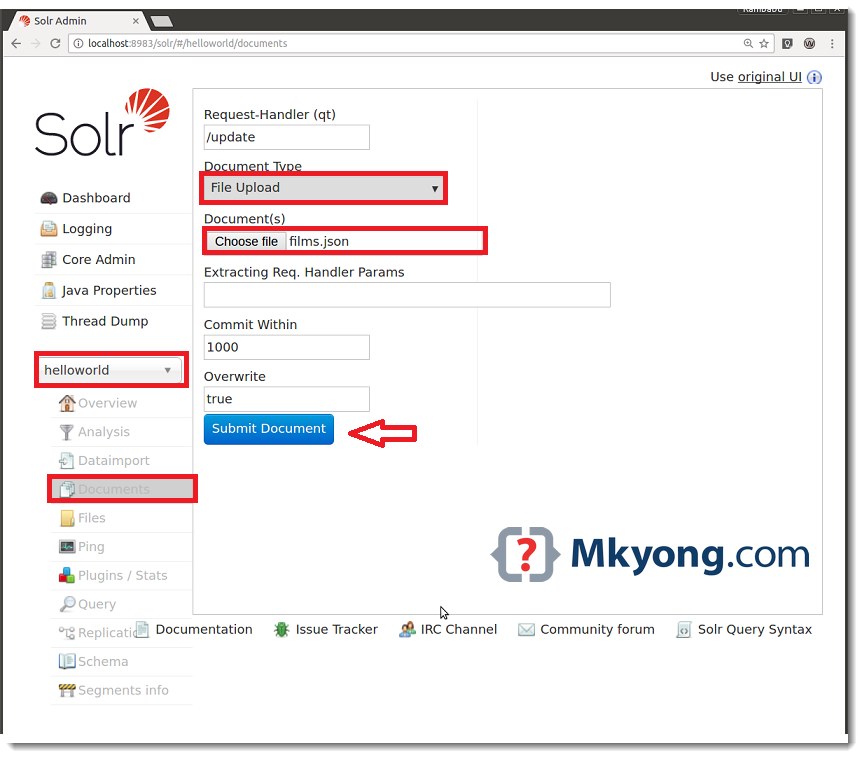
It creates a Document with available data in films.json file. We can do the same thing using xml, csv etc. files.
7. Query Documents from Core
We can use either REST API or Admin Console to query Documents from an Apache Core.
Let us explore it using Apache Admin Console now.
- Access Solr Admin Console:
http://localhost:8983/solr/ - Click on “Core Selector” option and select “helloworld” core in dropdown box.
- Click on “Query” from the left side panel
- Observe “Request-Handler”, it shows “/select” that means we are going to select or retrieve Documents from Core.
- Click on “Execute Query” button from the right side pannel
- It retrieves all available documents from “helloworld” core
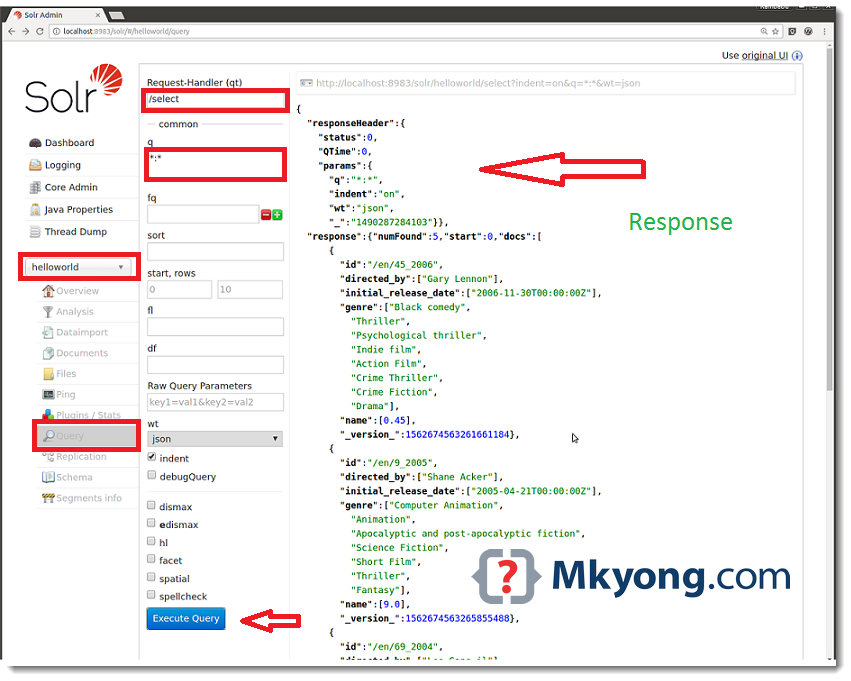
You can access same results using the following REST API call. You will see same the results on the Browser or REST Client.
http://localhost:8983/solr/helloworld/select?indent=on&q=*:*&wt=json
Here “q” represents “query parameters to filter the data. It uses “q=Fieldname:Value” syntax. Here “q=*:*” means query everything. “wt” means “writer type” or “Response type”.
Now let us query with some filtering options. You can access this REST API from Web Browser or any REST Clients like POSTMAN, Sense, Fidler etc.
http://localhost:8983/solr/helloworld/select?indent=on&q=directed_by:"Gary Lennon"&wt=json
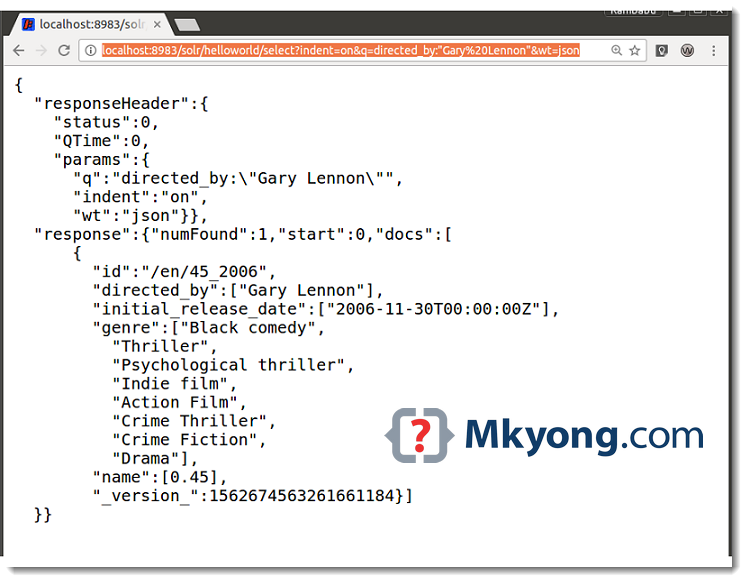
Here we have retrieved all Data from Films Document, which are matching this query directed_by=”Gary Lennon”. If you are good in SQL, we can convert this query into the following SQL SELECT command.
SELECT * FROM FILMS WHERE directed_by="Gary Lennon"
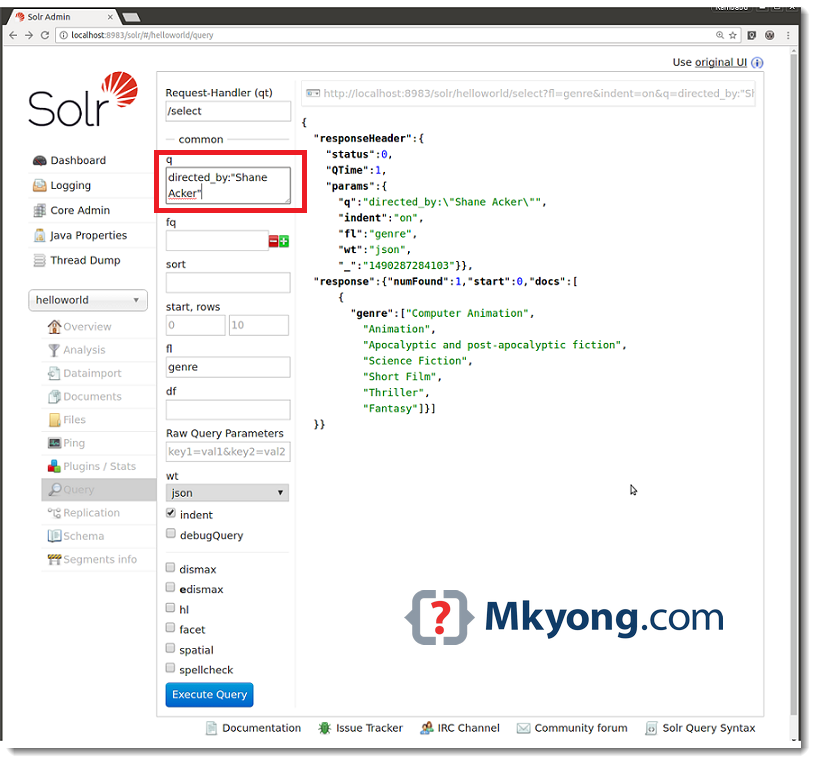
You can access same results using the following REST API call. You will see the same results on the Browser or REST Client.
http://localhost:8983/solr/helloworld/select?fl=genre&indent=on&q=directed_by:"Shane Acker"&wt=json
Here “fl” stands for Fields List in Response or Results. We are interested to retrieve only “genre” field. Convert this into SQL Query.
SELECT genre FROM FILMS WHERE directed_by="Shane Acker"
In the same way, please try to experiment with different SELECT queries to retrieve or filter data.
8. Delete Apache Solr Documents
Here we are going to delete one document which matches directed_by=”Zack Snyder” condition. We use same “Request-Handler” = “/update” that means we are going to update the Core. We use “
Here we are using curl command to perform DELETE operation to cover CURL command example too. You can experiment this example with other options like REST client etc.
$ curl http://localhost:8983/solr/helloworld/update/?commit=true -H "Content-Type: application/xml" -d "<delete><query>directed_by:'Zack Snyder'</query></delete>"
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader"><int name="status">0</int><int name="QTime">563</int></lst>
</response>
9. Delete Apache Solr Core
We can update Apache Solr Core by using “Request-Handler” = “/update” and doing add/update/delete operations on Documents. We can use either REST API on Browser, Admin Console, REST Client or CURL command to do this. If required, we can remove or delete Cores by using “Unload” option from Apache Solr Admin Console.
Please follow these steps to Unload a Core
- Access Solr Admin Console:
http://localhost:8983/solr/ - Click on “Core Selector” option and select “helloworld” core in the dropdown box.
- Click on “Unload” button from the right side panel.
- It removes or unload the selected core from Apache Solr.
- It does not delete the Core folder from “server/solr” path.
10. Why Apache Solr? Why Not Apache Lucene?
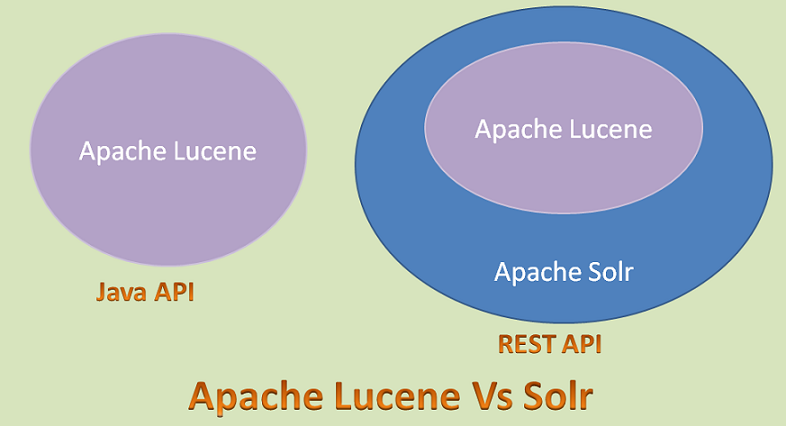
As we know, Apache Lucene is the basic Core API for both popular Search Engines: Apache Solr and ElasticSearch. However, Apache Lucene is a plain Java API and useful only for Java-Based Applications.
Like ElasticSearch, Apache Solr is a wrapper on top of the Apache Lucene API. It has exposed that Java API as REST API as shown in the below diagram. Now we can use this Search API in any applications. And also REST API is very flexible and light weight.
11. Apache Solr Vs ElasticSearch Vs Relational Databases
As we know, both Apache Solr and ElasticSearch use Apache Lucene to implement their Core Functionalities. Almost both support same features. Some notable similarities:
- Both uses Apache Lucene under-the-hood.
- Both supports REST Base API.
- Both are Open Source Search Engines.
- Both suppor BigData and Cloud Technologies.
- Both Support Cluster management.
- Both are useful as Secondary Data Stores.
- Both uses Apache Lucene’s Inverted Indexing to support the fast Searching feature.
They have the following differences.
- Apache Solr uses some external Component: SolrCloud to support Cloud and Distributed Architecture where as ElasticSearch has in-built and supports true Cloud and Distributed Architecture.
- Apache Solr uses Apache Zookeepter for Cluster Management where as ElasticSearch uses Zen Discovery for this.
- ElasticSearch supports only JSNO based REST API where as Apache Solr supports many more formats like JSON,XML, Doc, CSV, Binary etc.
- Apache Solr has in-built Security support where as ElasticSearch does not have.
- ElasticSearch supports only Schema-less data store where as Apache Solr supports both Schema-based and Schema less.
Differences between Apache Solr and Relational Databases
- Relational Databases support only Structured data where as Apache Solr both Structured and Un-Structured Data.
- Relational Databases are good for Normalized data where as Apache Solr is good for De-Normalized Data.
- Relational Databases needs Schema to store its data where as Apache Solr supports both Schema-based and Schema less.
- Relational Databases support complex queries and joins where as Apache Solr has not supported them.
- We can use Relational Databases as Primary Data Store where Apache Solr as Secondary Data Store.
Nice Information about solr
Really good tutorial. I was having trouble with a tutorial by another person and found yours. Your tutorial showed me what was wrong with the other tutorial! Thanks!
What does it mean “In Standalone mode, Solr contains only one instance where as in Cloud mode, it contains one or more instances.”.
Can someone explain with example?
Thanks,
Jay
Hi Ram, The environment variable setting of SOLR_HOME has some issues. If I set my SOLR_HOME as mentioned in your tutorial then on running the command solr start from the {SOLR installation directory}/bin it gives error: “Error: Solr home directory E:\myDirectory\solr-7.2.1\solr-7.2.1 must contain solr.xml file” . Are you sure we can set the Environment variable for SOLR_HOME through Windows Path option as you mentioned? What could be the issue on my side then?
copy solr.xml from solr-7.6.0\\server\\solr\\solr.xml into SOLR_HOME, will work. i got same error and copied and started fine.
Nice tutorial, but many typing mistakes.
Really single web page to get all your basic query Answered for beginners. Thanks a lot !!!!!!
Can we Integrate SOlAR with API Integration like instead of uploading the document through file system can we upload through Mule Server and Integrate
Access Solr Admin Console: http://localhost:8983/solr/
Click on “Core Selector” option and select “helloworld” core in dropdown box.
Click on “Documents” option
Observe “Request-Handler”, it shows “/update” that means we are going to update Core with Documents
At Document(s), click on “Choose File” option
Select “films.json” from ${SOLR_HOME}/example/films/
Click on “Submit Document” button.
i am getting a exception
Status: failure
Response:
{
“responseHeader”: {
“status”: 415,
“QTime”: 57
},
“error”: {
“metadata”: [
“error-class”,
“org.apache.solr.common.SolrException”,
“root-error-class”,
“org.apache.solr.common.SolrException”
],
“msg”: “Unsupported ContentType: application/octet-stream Not in: [application/xml, application/csv, application/json, text/json, text/csv, text/xml, application/javabin]”,
“code”: 415
}
}
What are the thought behind this statement: “Not useful as a Primary Data Store. Only useful as Secondary Data Store.”
Why can’t Solr be used as the primary database?
The point here is not about if you can or can’t use it. You can implement your system using Solr as a primary database, but the Solr focus is to indexing. You have better performance and a lot of functions in relational databases or NoSQL databases that encorage developers to use them instead Solr or Elastic on their systems for CRUD operations.
This is a really nice guide, but there’s a LOT of typos which detracts and distracts from the quality of this piece.